![]()
最新のCompTIA DA0-001日本語のPDFと問題集で(2025)無料試験問題解答
あなたを合格させるCompTIA Data+ DA0-001日本語試験問題集で2025年03月19日には312問あります
質問 # 49
ある企業は、商品のクリック数に基づいて、顧客が電子商取引 Web サイトとどのようにやり取りしているかを把握したいと考えています。
このレポートの主な要件は次のどれですか?
- A. データ内容
- B. ビュー
- C. フィルタリング
- D. 頻度
正解:D
質問 # 50
Data+ 試験の最低合格スコアは?
- A. 0
- B. 1
- C. 2
- D. 3
正解:B
質問 # 51
以下のデータがあるとします。
データは次のどのファイル形式で表示されますか?
- A. Xs
- B. CSV
- C. RIF
- D. XML
正解:B
解説:
Explanation
The data is presented in a CSV (comma-separated values) file format, which is a plain text format that stores tabular data. Each line of the file is a data record, and each record consists of one or more fields separated by commas. The first line of the file usually contains the names of the fields, also known as the header. In this case, the data has four fields: Name, Age, Gender, and Occupation. Therefore, the correct answer is B.
References: CSV File (What It Is & How to Open One), Comma-separated values - Wikipedia
質問 # 52
次のうち、計算とピボット テーブルに使用されるものはどれですか?
- A. IBM SPSS
- B. SAS
- C. どーも
- D. マイクロソフト エクセル
正解:D
質問 # 53
アナリストは IT ドキュメントを作成し、そのドキュメントで使用される技術用語を説明する必要があります。アナリストが技術用語の説明を含める必要があるのは次のうちどれですか?
- A. システム図
- B. ユーザー要件
- C. インデックス
- D. 用語集
正解:D
質問 # 54
次のデータがあるとします。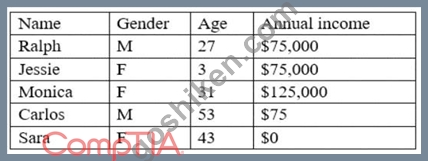
次のうち、データセットを最もよく表しているのはどれですか?
- A. データに偏りがあります。
- B. データが不完全です。
- C. データは外れ値です。
- D. データに不整合があります。
正解:D
解説:
Explanation
This is because inconsistency is a type of data quality issue that occurs when the data does not follow a common format, structure, or rule across different sources or systems, which can affect the efficiency and performance of the analysis or process. Inconsistency can be caused by having different spellings, punctuations, capitalizations, or abbreviations for the same or similar values in a data set, such as "M", "m",
"Male", or "male" for gender in this case. Inconsistency can be eliminated or reduced by using data cleansing techniques, such as standardizing or normalizing the data values. The other options are not correct descriptions of the data set. Here is why:
Data bias is a type of data quality issue that occurs when the data is not representative or proportional of the population or the parameter, which can affect the validity and reliability of the analysis or process.
Data bias can be caused by having a sample that is too small, too large, or too skewed for the population or the parameter, such as having only male customers for a product that targets both genders in this case.
Data bias can be eliminated or reduced by using sampling techniques, such as stratified or cluster sampling.
The data is incomplete is a type of data quality issue that occurs when the data is absent or missing in a data set, which can affect the accuracy and reliability of the analysis or process. The data is incomplete can be caused by various factors, such as human error, system error, or non-response. The data is incomplete can be addressed by using various methods, such as replacing or imputing the missing values with some reasonable estimates, such as mean, median, mode, or regression.
The data is outliers is a type of data quality issue that occurs when the data has values that are unusually high or low compared to the rest of the data set, which can affect the quality and validity of the analysis or process. The data is outliers can be caused by various factors, such as measurement error, natural variation, or extreme events. The data is outliers can be addressed by using various methods, such as removing or filtering out the outliers, or using robust statistics that are less sensitive to outliers, such as median, interquartile range, or box plot.
質問 # 55
次のうち、個人を特定できない情報と見なされるのはどれですか?
- A. 政府 ID 番号
- B. 電話番号
- C. 携帯電話のデバイス名
- D. お客様のお名前
正解:C
質問 # 56
Chris は、レストランのメニュー項目の価格を保存するためのデータベースを構築しています。
このフィールドに最も適したデータ型は?
- A. タグ。
- B. 数値。
- C. 日付。
- D. 英数字。
正解:B
解説:
Prices are numbers stored in dollars and cents; as such, the data type needs to be capable of storing numbers.
質問 # 57
新しいツールを入手することを意味する場合でも、特定の状況に最も適した分析ツールを常に選択する必要があります。
- A. そうです。
- B. いいえ。
正解:B
質問 # 58
コール センターが 1 日に受け取る電話の数は、次のようなものです。
- A. 離散データ。
- B. カテゴリ データ。
- C. 連続データ。
- D. 順序データ。
正解:A
質問 # 59
次のデータが与えられます: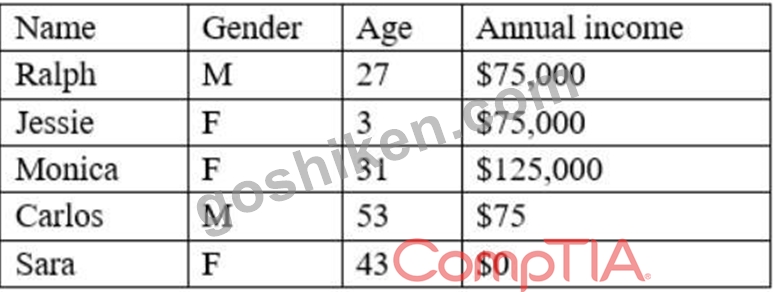
次のどれがデータセットを最もよく説明していますか?
- A. データに偏りがあります。
- B. データに矛盾があります。
- C. データが不完全です。
- D. データは外れ値です。
正解:B
解説:
This is because inconsistency is a type of data quality issue that occurs when the data does not follow a common format, structure, or rule across different sources or systems, which can affect the efficiency and performance of the analysis or process. Inconsistency can be caused by having different spellings, punctuations, capitalizations, or abbreviations for the same or similar values in a data set, such as "M", "m",
"Male", or "male" for gender in this case. Inconsistency can be eliminated or reduced by using data cleansing techniques, such as standardizing or normalizing the data values. The other options are not correct descriptions of the data set. Here is why:
* Data bias is a type of data quality issue that occurs when the data is not representative or proportional of the population or the parameter, which can affect the validity and reliability of the analysis or process.
Data bias can be caused by having a sample that is too small, too large, or too skewed for the population or the parameter, such as having only male customers for a product that targets both genders in this case. Data bias can be eliminated or reduced by using sampling techniques, such as stratified or cluster sampling.
* The data is incomplete is a type of data quality issue that occurs when the data is absent or missing in a data set, which can affect the accuracy and reliability of the analysis or process. The data is incomplete can be caused by various factors, such as human error, system error, or non-response. The data is incomplete can be addressed by using various methods, such as replacing or imputing the missing values with some reasonable estimates, such as mean, median, mode, or regression.
* The data is outliers is a type of data quality issue that occurs when the data has values that are unusually high or low compared to the rest of the data set, which can affect the quality and validity of the analysis or process. The data is outliers can be caused by various factors, such as measurement error, natural variation, or extreme events. The data is outliers can be addressed by using various methods, such as removing or filtering out the outliers, or using robust statistics that are less sensitive to outliers, such as median, interquartile range, or box plot.
質問 # 60
アナリストは、従業員イントラネット サイトの分析ダッシュボードを作成して、検索機能を改善し、関連情報を表示し、最新の FAQ ページを維持する必要があります。次のビジュアライゼーションのうち、従業員が探しているものを最もよく表すものはどれですか?
- A. ヒストグラム
- B. ワード クラウド
- C. 円グラフ
- D. 散布図
正解:B
解説:
A word cloud is an ideal choice for visualizing what employees are searching for on an intranet site. It represents the frequency of word occurrence in a visually impactful way, with more commonly searched terms appearing larger in the cloud. This allows for quick identification of the most popular queries and topics of interest among employees. Unlike histograms, pie charts, or scatter plots, word clouds can effectively display textual data, which is the nature of search queries. They are particularly useful for analyzing text data from surveys or feedback forms, which can be similar to search query data in an intranet environment1234.
References: 1: "What Are Word Clouds? Pros & Cons of Word Cloud Visualizations" - Alida 2: "Using Word Clouds for Powerful Data Visualization" - WordCloud.app blog 3: "Ultimate Google Data Studio Word Cloud Guide: Visualization 2024" - AtOnce 4: "How to Create Word Cloud in Power BI" - Zebra BI
質問 # 61
公開グループは、公開前に投稿を追跡するためのダッシュボードを要求しました。重要な要件は、すべての変更が追跡されることです。これは、複数のユーザーがドキュメントをチェックアウトし、提出が最終と見なされる前にそれらを編集するためです。この利害関係者の要件を満たすための最良の方法は次のうちどれですか?
- A. ダッシュボードの各申請の横にバージョン番号を表示します。
- B. アクセス許可を使用して、ユーザーが提出物の特定のバージョンのみを表示できるようにします。
- C. ダッシュボードがコーポレート スタイル ガイドに準拠していることを確認します。
- D. ダッシュボードの上部にデータ更新日を表示します。
正解:A
解説:
Explanation
A static report is a type of report that shows a snapshot of data at a specific point in time. A static report does not change or update automatically, unless the data source is refreshed or the report is regenerated. A static report is suitable for situations where the data does not change frequently or where historical data is needed for comparison or analysis. In this case, the data analyst is asked to create a sales report for the second-quarter
2020 board meeting, which will include a review of the business's performance through the second quarter.
The board meeting will be held on July 15, 2020, after the numbers are finalized. This means that the data analyst does not need to show real-time or dynamic data, but rather a fixed and accurate view of the sales data for the second quarter. Therefore, a static report would be the best way to meet this stakeholder requirement.
Therefore, the correct answer is A. References: What are Static Reports? | Sisense, Static vs Dynamic Reports
- What's The Difference? | datapine
質問 # 62
営業アナリストは、営業チームの目標達成状況を報告する必要があります。2019 年のパフォーマンスの達成を決定する上で重要となるファイルは次のうちどれですか?
- A. 2019年度手数料計画
- B. 2018 年の実際の収益
- C. 2018年の目標データ
- D. 2019年の目標データ
正解:D
解説:
Explanation
answer: C. 2019 goal data
To report how the sales team is performing to target, the sales analyst needs to compare the actual sales revenue with the expected or planned sales revenue for the same period. The 2019 goal data is the file that contains the expected or planned sales revenue for the year 2019, which is the target that the sales team is aiming to achieve. By comparing the 2019 goal data with the 2019 actual revenue, the sales analyst can calculate the performance attainment, which is the percentage of the goal that was met by the sales team.
Option A is incorrect, as 2018 goal data is not relevant for determining 2019 performance attainment. The
2018 goal data contains the expected or planned sales revenue for the year 2018, which is not the target that the sales team is aiming to achieve in 2019.
Option B is incorrect, as 2018 actual revenue is not relevant for determining 2019 performance attainment.
The 2018 actual revenue contains the actual sales revenue for the year 2018, which is not comparable with the
2019 goal data or the 2019 actual revenue.
Option D is incorrect, as 2019 commission plan is not relevant for determining 2019 performance attainment.
The 2019 commission plan contains the rules and rates for calculating and paying commissions to the sales team based on their performance attainment, but it does not contain the expected or planned sales revenue for the year 2019.
質問 # 63
通常、要約統計量と見なされないものは次のうちどれですか?
- A. 分散。
- B. 意地悪。
- C. z スコア。
- D. 標準偏差。
正解:C
解説:
Explanation:
Simply put, a z-score (also called a standard score) gives you an idea of how far from the mean a data point is. But more technically it's a measure of how many standard deviations below or above the population mean a raw score is. A z-score can be placed on a normal distribution curve.
質問 # 64
テイラーは、製造、マーケティング、および販売の支出が会社の全体的な収益性にどのように影響するかを調査したいと考えています。
次のシステムのうち、最も適切なものはどれですか?
- A. OLTP.
- B. Data mart.
- C. OLAP.
- D. Data warehouse.
正解:D
解説:
Explanation
A Data mart is too narrow, because Taylor needs data from across multiple divisions.
OLAP is a broad term for analytical processing, and OLTP systems are transactional and not ideal for the task.
Since Taylor is working with data across multiple different divisions, she will work with a Data warehouse.
質問 # 65
アナリストは、データ品質の検証を依頼されました。品質管理の目的でデータを検証する最も良い理由は次のうちどれですか? (2つ選んでください。)
- A. 一貫性
- B. 削除
- C. 保持
- D. 暗号化
- E. 整合性
- F. 送信
正解:A、E
質問 # 66
営業ディレクターが、部門内の個々のチーム メンバー向けのレポートを作成するように要求しました。ディレクターは、レポートをすべてのチーム メンバーと共有したいと考えていますが、レポート内で個々のチーム メンバーが特定されるべきではありません。 次のアクセス要件のうち、ディレクターのニーズをサポートするものはどれですか?
- A. 販売データの利用規定を作成します。
- B. 役割に基づいてレポートを提供し、データ暗号化を含めます。
- C. 各チーム メンバーからデータ使用契約を取得します。
- D. レポートをユーザー グループ ベースのアクセスとしてリリースし、データ マスキングを含めます。
正解:D
質問 # 67
潜在顧客を開拓している営業担当者が次のデータを収集しました。
このデータに関して問題となるのは次のどれですか?
- A. 重複データ
- B. 冗長データ
- C. 無効なデータ
- D. 値が欠落しています
正解:D
質問 # 68
メディア企業のデータ アナリストは、最も人気のある映画のジャンルを特定する必要があります。以下の表を考えると: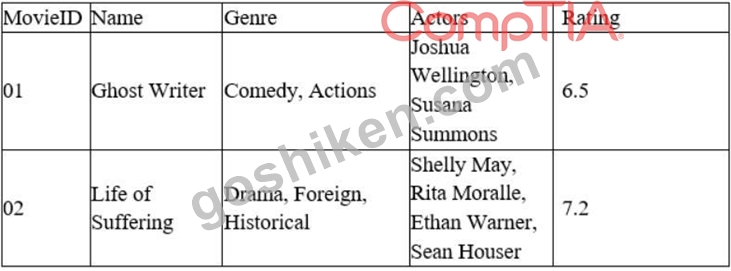
このタスクを完了する前に、ジャンル列に対して行う必要があるのは次のうちどれですか?
- A. マージ
- B. 区切り
- C. 連結
- D. 追加
正解:B
解説:
Delimiting is the process of splitting a column of data into multiple columns based on a separator or delimiter character. Delimiting can help separate data that is combined or concatenated in one column into distinct values or categories. For example, if a column contains text values that are separated by commas, such as
"Comedy, Suspense", delimiting can split this column into two columns, one for "Comedy" and one for
"Suspense". Delimiting is different from other options, such as appending, merging, or concatenating, which are methods of combining or joining data from multiple columns or sources. In this case, the data analyst needs to determine the most popular movie genre based on the Genre column in the table. However, this column contains multiple genres for each movie, separated by commas. Therefore, the data analyst must delimit this column before this task can be completed. Therefore, the correct answer is D. References: Split text into different columns with functions - Office Support, How to Split Text in Excel (Using Formulas & Split Function)
質問 # 69
調査では、参加者に企業を 1 から 10 のスケールで評価してもらいます。評価変数を最もよく表しているのは次のうちどれですか?
- A. カテゴリカル
- B. 連続
- C. 公称値
- D. 序数
正解:D
解説:
The rating variable in a survey where participants rate a company on a scale of one to ten is best described as ordinal. This is because the ratings are ranked in order, with each number representing a position on a scale of satisfaction or quality. The numbers are not just labels (which would be nominal), nor do they represent a continuous spectrum (which would be continuous). They also do not fit the definition of categorical, as that implies non-ordered groups or categories. In an ordinal scale, the order of the values is significant and meaningful12.
References:
* Qualtrics explains that ordinal scales have answer sets that occur in a logical and systematic order, providing qualitative data.
* Zonka Feedback describes a 1 to 10 rating scale survey, indicating that the numbers represent a ranking from most negative to most positive experience, which aligns with the characteristics of an ordinal scale.
質問 # 70
データ アナリストは、オンライン マーケティング キャンペーンの結果をマーケティング マネージャーに提示する必要があります。マネージャーは、最も重要な KPI を確認し、マーケティングの投資収益率を測定したいと考えています。データ アナリストがこの情報をマネージャーに最もよく伝えるために使用する必要があるのは、次のうちどれですか?
- A. データ アナリストからの統計、結論、および推奨事項を含む概要
- B. キャンペーンが開始された日のパフォーマンスを管理者が確認できるリアルタイム モニター
- C. 管理者が会社の年間予算実績を確認できる販売サービス ダッシュボード
- D. すべてのマーケティング キャンペーンとチャネルからの生データのスプレッドシート
正解:A
解説:
Explanation
A summary with statistics, conclusions, and recommendations from the data analyst is the best way to communicate the results of an online marketing campaign to the marketing manager. A summary can provide a concise and clear overview of the most important KPIs and measure the return on marketing investment, as well as highlight the main findings and insights from the data analysis. A summary can also include actionable suggestions and best practices for improving the campaign performance and achieving the marketing objectives. A summary is different from other options, such as a real-time monitor, a self-service dashboard, or a spreadsheet of raw data, which may not provide enough context, interpretation, or guidance for the manager.
Therefore, the correct answer is D. References: How to Write a Data Analysis Report: 6 Essential Tips, How to Write a Marketing Report (with Pictures) - wikiHow
質問 # 71
データ アナリストは、以下の表のデータ セットを使用して、各生徒の学習時間と試験の点数の関係を示すグラフを作成するように依頼されました。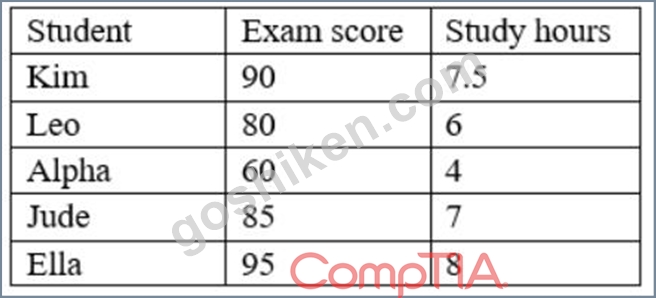
次のグラフのうち、変数間の関係を最もよく表しているのはどれですか?
- A. ヒストグラム
- B. ヒートマップ
- C. 棒グラフ
- D. 散布図
正解:D
解説:
This is because a scatter plot is a type of chart that shows the relationship between two variables for each observation or unit in a data set, such as study hours and exam scores for each student in this case. A scatter plot can be used to display and analyze the correlation, trend, or pattern among the variables, as well as identify any outliers or clusters in the data. For example, a scatter plot can show if there is a positive, negative, or no correlation between study hours and exam scores, as well as show if there are any students who have unusually high or low exam scores compared to their study hours. The other charts are not the best charts to represent the relationship between the variables. Here is why:
A histogram is a type of chart that shows the frequency or the count of values in a single variable for different intervals or bins, such as exam scores for different ranges in this case. A histogram can be used to display and analyze the distribution, shape, or spread of the variable, as well as identify any gaps, peaks, or skewness in the data. For example, a histogram can show if most students have high, low, or average exam scores, as well as show if there are any intervals that have no students at all.
A heat map is a type of chart that shows the intensity or the magnitude of values in two variables for different categories or groups, such as exam scores and study hours for different student names in this case. A heat map can be used to display and analyze the variation, contrast, or comparison among the categories or groups, as well as identify any hot spots, cold spots, or gradients in the data. For example, a heat map can show which students have higher or lower exam scores and study hours than others, as well as show if there is a color pattern that indicates a relationship between exam scores and study hours.
A bar chart is a type of chart that shows the value or the amount of a single variable for different categories or groups, such as exam scores for different student names in this case. A bar chart can be used to display and analyze the comparison, ranking, or proportion among the categories or groups, as well as identify any differences, similarities, or outliers in the data. For example, a bar chart can show which students have higher or lower exam scores than others, as well as show if there are any students who have exceptionally high or low exam scores.
質問 # 72
リレーショナル データ ストリーム管理システムに保持されるデータを管理するために設計された、プログラミングで使用されるドメイン固有言語は次のうちどれですか?
- A. R
- B. SAS
- C. SQL
- D. Python
正解:C
解説:
SQL (Structured Query Language) is a domain-specific language used in programming, specifically designed for managing data held in a relational database management system (RDBMS), or for stream processing in a relational data stream management system (RDSMS). It is the standard language for relational database management systems. SQL statements are used to perform tasks such as update data on a database, or retrieve data from a database. Unlike languages like Python or R, which are general-purpose programming languages, SQL is tailored specifically for database management and manipulation.
References:
* ResearchGate article on SQL1.
* SpringerLink chapter on Relational Databases and SQL Language2.
* DataCamp tutorial on SQL Server Installation3.
* Wikipedia page on SQL4.
質問 # 73
......
DA0-001日本語問題集はCompTIA Data+認証済み試験問題と解答:https://www.goshiken.com/CompTIA/DA0-001J-mondaishu.html