![]()
AWS-Solutions-Associate日本語試験問題を今すぐ試そう!最新の[2023年最新] 正解回答付き
練習できるAWS-Solutions-Associate日本語には認定ガイド問題と解答とトレーニングを提供しています
質問 # 121
ソリューションアーキテクトは、非常に高い順次I / Oを必要とするビッグデータアプリケーションのストレージタイプを選択する必要があります。インスタンスが停止した場合、データは持続する必要があります。
次のストレージタイプのうち、アプリケーションの最低コストで最適なストレージタイプはどれですか?
- A. Amazon EBS汎用SSDボリューム。
- B. ローカルSSDボリュームを格納するAmazon EC2インスタンス。
- C. Amazon EBSがプロビジョニングしたIOPS SSDボリューム。
- D. Amazon EBSスループット最適化HDDボリューム。
正解:D
質問 # 122
企業は、アプリケーション ログを Amazon CloudWatch Logs ログ グループに保存します。新しいポリシーでは、会社はすべてのアプリケーション ログを Amazon OpenSearch Service (Amazon Elasticsearch Service) にほぼリアルタイムで保存する必要があります。
運用上のオーバーヘッドが最も少なく、この要件を満たすソリューションはどれですか?
- A. Amazon Kinesis Data Firehose 配信ストリームを作成します。配信ストリームのソースとしてログ グループを構成します。配信ストリームの宛先として Amazon OpenSearch Service (Amazon Elasticsearch Service) を設定します。
- B. CloudWatch Logs サブスクリプションを構成して、ログを Amazon OpenSearch Service (Amazon Elasticsearch Service) にストリーミングします。
- C. AWS Lambda 関数を作成します。ログ グループを使用して関数を呼び出し、ログを Amazon OpenSearch Service (Amazon Elasticsearch Service) に書き込みます。
- D. 各アプリケーション サーバーに Amazon Kinesis エージェントをインストールして構成し、ログを Amazon Kinesis Data Streams に配信します。ログを Amazon OpenSearch Service (Amazon Elasticsearch Service) に配信するように Kinesis Data Streams を設定する
正解:C
解説:
Explanation
https://computingforgeeks.com/stream-logs-in-aws-from-cloudwatch-to-elasticsearch/
質問 # 123
ソリューションアーキテクトは、Amazon S3に大量のイベントデータを保存するソリューションを設計しています。
アーキテクトは、ワークロードが常に毎秒100リクエストを超えると予想しています。
パフォーマンスを最適化するために、アーキテクトはAmazon S3で何をすべきですか?
- A. Amazon S3 Transfer Accelerationを使用します。
- B. イベントデータを個別のバケットに保存します。
- C. キー名のプレフィックスをランダム化します。
- D. キー名のサフィックスをランダム化します。
正解:C
解説:
Explanation
https://docs.aws.amazon.com/AmazonS3/latest/dev/request-rate-perf-considerations.html
質問 # 124
ある会社がデータキャンターに反抗しており、AWS * ilhm2週間で50TBのデータを安全に転送したいと考えています。
既存のデータセンターには、90%使用されているAWSへのサイト間VPN接続があります。ソリューションアーキテクトがこれらの要件を満たすために使用する必要があるAWSサービスはどれですか。
- A. VPCエンドポイントを使用したAWS DataSync
- B. AWS Direct Conned
- C. AWS Storage Gateway
- D. AWS Snowball EdgeStorageが最適化されました
正解:D
質問 # 125
アプリケーションは、複数のアベイラビリティーゾーンにまたがるAmazon EC2インスタンスで実行されます。インスタンスは、Application Load Balancerの背後にあるAmazon EC2 Auto Scalingグループで実行されます。アプリケーションは、EC2インスタンスのCPU使用率が40%以下のときに最高のパフォーマンスを発揮します。グループ内のすべてのインスタンスにわたって望ましいパフォーマンスを維持するには?
- A. スケジュールされたスケーリングアクションを使用して、Auto Scalingグループをスケールアップおよびスケールダウンします
- B. 単純なスケーリングポリシーを使用してAuto Scalingグループを動的にスケーリングします
- C. AWS Lambda関数を使用して、目的のAuto Scalingグループ容量を更新します
- D. ターゲットトラッキングポリシーを使用して、Auto Scalingグループを動的にスケーリングします
正解:D
質問 # 126 
- A. Option A
- B. Option C
- C. Option D
- D. Option B
正解:D
質問 # 127
ソリューションアーキテクトは、ストレージにAmazon S3バケットを使用してドキュメントレビューアプリケーションを実装しています。ソリューションは、ドキュメントの誤った削除を防止し、ドキュメントのすべてのバージョンが利用可能であることを確認する必要があります。ユーザーはドキュメントをダウンロード、変更、アップロードできる必要があります。これらの要件を満たすためにアクションを実行する必要がありますか? (2つ選択)
- A. AWS KMSを使用してバケットを暗号化します
- B. バケットでMFA削除を有効にする
- C. バケットのバージョニングを有効にします
- D. 読み取り専用バケットACLを有効にします
- E. 1AMポリシーをバケットにアタッチします
正解:B、C
解説:
Explanation
Object Versioning
Use Amazon S3 Versioning to keep multiple versions of an object in one bucket. For example, you could store my-image.jpg (version 111111) and my-image.jpg (version 222222) in a single bucket. S3 Versioning protects you from the consequences of unintended overwrites and deletions. You can also use it to archive objects so that you have access to previous versions.
To customize your data retention approach and control storage costs, use object versioning with Object lifecycle management. For information about creating S3 Lifecycle policies using the AWS Management Console, see How Do I Create a Lifecycle Policy for an S3 Bucket? in the Amazon Simple Storage Service Console User Guide.
If you have an object expiration lifecycle policy in your non-versioned bucket and you want to maintain the same permanent delete behavior when you enable versioning, you must add a noncurrent expiration policy.
The noncurrent expiration lifecycle policy will manage the deletes of the noncurrent object versions in the version-enabled bucket. (A version-enabled bucket maintains one current and zero or more noncurrent object versions.) You must explicitly enable S3 Versioning on your bucket. By default, S3 Versioning is disabled. Regardless of whether you have enabled Versioning, each object in your bucket has a version ID. If you have not enabled Versioning, Amazon S3 sets the value of the version ID to null. If S3 Versioning is enabled, Amazon S3 assigns a version ID value for the object. This value distinguishes it from other versions of the same key.
Enabling and suspending versioning is done at the bucket level. When you enable versioning on an existing bucket, objects that are already stored in the bucket are unchanged. The version IDs (null), contents, and permissions remain the same. After you enable S3 Versioning for a bucket, each object that is added to the bucket gets a version ID, which distinguishes it from other versions of the same key.
Only Amazon S3 generates version IDs, and they can't be edited. Version IDs are Unicode, UTF-8 encoded, URL-ready, opaque strings that are no more than 1,024 bytes long. The following is an example:
3/L4kqtJlcpXroDTDmJ+rmSpXd3dIbrHY+MTRCxf3vjVBH40Nr8X8gdRQBpUMLUo.
Using MFA delete
If a bucket's versioning configuration is MFA Delete-enabled, the bucket owner must include the x-amz-mfa request header in requests to permanently delete an object version or change the versioning state of the bucket.
Requests that include x-amz-mfa must use HTTPS. The header's value is the concatenation of your authentication device's serial number, a space, and the authentication code displayed on it. If you do not include this request header, the request fails.
https://docs.aws.amazon.com/AmazonS3/latest/dev/ObjectVersioning.html
https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingMFADelete.html
質問 # 128
ある会社は、AWS で e コマース Web サイトのプロトタイプを作成しています。このウェブサイトは、Application Load Balancer、ウェブサーバー用の Amazon EC2 インスタンスの Auto Scaling グループ、およびシングル AZ 構成で実行される Amazon RDS for MySQL DB インスタンスで構成されています。製品カタログの検索中、ウェブサイトの応答が遅くなります。製品カタログは、会社が頻繁に更新しない MySQL データベース内のテーブルのグループです。ソリューション アーキテクトは、製品カタログの検索が行われるときに DB インスタンスの CPU 使用率が高いと判断しました。製品カタログの検索中にウェブサイト?
- A. 製品カタログを Amazon Redshift データベースに移行する COPY コマンドを使用して製品カタログ テーブルをロードする
- B. Auto Scaling グループに追加のスケーリング ポリシーを追加して、データベースの応答が遅い場合に追加の EC2 インスタンスを起動します。
- C. Amazon ElastiCache for Redis クラスターを実装して製品カタログをキャッシュする 遅延読み込みを使用してキャッシュに入力する
- D. DB インスタンスのマルチ AZ 設定を有効にします データベースに送信される製品カタログ クエリを調整するように EC2 インスタンスを設定します
正解:C
質問 # 129 
- A. Amazon Simple Storage Service (S3)
- B. Amazon DynamoDB
- C. Amazon Elastic Compute Cloud (EC2)
- D. Amazon Elastic Load Balancing
- E. Amazon Simple Notification Service (SNS)
正解:C、D
質問 # 130
Solution Architectは3層Webアプリケーションを設計しています。アーキテクトは、データベース層へのアクセスを制限して、アプリケーションサーバーからのトラフィックのみを受け付けるようにします。ただし、これらのアプリケーションサーバーはAuto Scalingグループに属しており、数量が異なる場合があります。
アーキテクトはどのようにして要件を満たすようにデータベースサーバーを構成すべきですか?
- A. アプリケーション層サブネットからの受信データベーストラフィックを許可するようにデータベースサブネットネットワークACLを設定します。
- B. アプリケーションサーバーセキュリティグループからのデータベーストラフィックを許可するようにデータベースセキュリティグループを設定します。
- C. アプリケーションサーバーのIPアドレスからのデータベーストラフィックを許可するようにデータベースセキュリティグループを設定します。
- D. アプリケーションサブネットからのすべてのデータベース以外の受信トラフィックを拒否するようにデータベースサブネットネットワークACLを設定します。
正解:D
質問 # 131
3つのアベイラビリティーゾーンにまたがって、フォールトトレラントでスケーラブルなWebアプリケーションを設計するように求められました。
プレゼンテーションロジックはWebサーバーのELB Classic Load Balanceの背後にあり、アプリケーションロジックは2番目のロードバランサーの背後にある一連のアプリサーバーにあります。
Auto Scalingグループをどのように使用する必要がありますか?
- A. 6つのAuto Scalingグループをデプロイします:各アベイラビリティーゾーンのWebサーバーグループと各アベイラビリティーゾーンのアプリサーバーグループ
- B. すべてのアベイラビリティーゾーンにわたるすべてのWebサーバーとアプリサーバーを含む1つのAuto Scalingグループを展開します
- C. 3つのAuto Scalingグループを展開します:Webサーバーとアプリサーバーの両方を含む各アベイラビリティーゾーンに1つ
- D. 2つのAuto Scalingグループをデプロイします。1つはすべてのアベイラビリティーゾーンのWebサーバー用で、もう1つはすべてのアベイラビリティーゾーンのアプリサーバー用です
正解:D
質問 # 132
ある会社は、ソリューションアーキテクトに、AWSがホストする内部アプリケーションを変更して負荷分散を可能にするように依頼しました。顧客のリクエストは常に会社のドメイン(example.net)から送信されます。会社は、要求内のURLのパス要素に基づいて、着信HTTPおよびHTTPSトラフィックをルーティングすることを要求しています。
どの実装がすべての要件を満たすことができますか?
- A. ネットワークロードバランサーを構成し、クロスゾーンロードバランシングを有効にして、すべてのEC2インスタンスが使用されるようにします。
- B. ターゲットグループの適切なパスパターンのリスナーでNetwork Load Balancerを構成します。
- C. HTTPヘッダーのドメインフィールドに基づいて、ホストベースのルーティングを使用してApplication Load Balancerを構成します。
- D. ターゲットグループの適切なパスパターンのリスナーでApplication Load Balancerを構成します。
正解:C
解説:
https://aws.amazon.com/blogs/aws/new-host-based-routing-support-for-aws-application-load-balancers/
質問 # 133
プライベートサブネットで実行されているアプリケーションは、Amazon DynamoDBテーブルにアクセスします。データがAWSネットワークを決して離れないというセキュリティ要件があります。
この要件はどのように満たされるべきですか?
- A. DynamoDBでネットワークACLを設定して、プライベートサブネットへのトラフィックを制限します
- B. DynamoDBのVPCエンドポイントを作成し、エンドポイントポリシーを構成します
- C. NATゲートウェイを追加し、プライベートサブネットにルートテーブルを構成します
- D. AWS KMSキーを使用して安静時にDynamoDB暗号化を有効にする
正解:B
解説:
Explanation
https://aws.amazon.com/es/blogs/aws/new-vpc-endpoints-for-dynamodb/
https://aws.amazon.com/blogs/database/how-to-configure-a-private-network-environment-for-amazon-dynamodb
質問 # 134
企業は複数のWebサイトからクリックストリームデータをキャプチャし、バッチ処理を使用してそれを分析します。データは毎晩Amazon Redshiftに読み込まれ、ビジネスアナリストによって使用されます。同社は、タイムリーな洞察を得るために、ほぼリアルタイムのデータ処理に移行したいと考えています。このソリューションでは、最小限の労力と運用オーバーヘッドでストリーミングデータを処理する必要があります。
このソリューションで最も費用効果の高いAWSサービスの組み合わせはどれですか? (2つ選択してください。)
- A. AWS Lambda
- B. Amazon EC2
- C. Amazon Kinesis Data Streams
- D. Amazon Kinesis Data Analytics
- E. Amazon Kinesis Data Firehose
正解:A、E
解説:
Explanation
Kinesis Data Streams and Kinesis Client Library (KCL) - Data from the data source can be continuously captured and streamed in near real-time using Kinesis Data Streams.
With the Kinesis Client Library (KCL), you can build your own application that can preprocess the streaming data as they arrive and emit the data for generating incremental views and downstream analysis.
Kinesis Data Analytics - This service provides the easiest way to process the data that is streaming through Kinesis Data Stream or Kinesis Data Firehose using SQL. This enables customers to gain actionable insight in near real-time from the incremental stream before storing it in Amazon S3.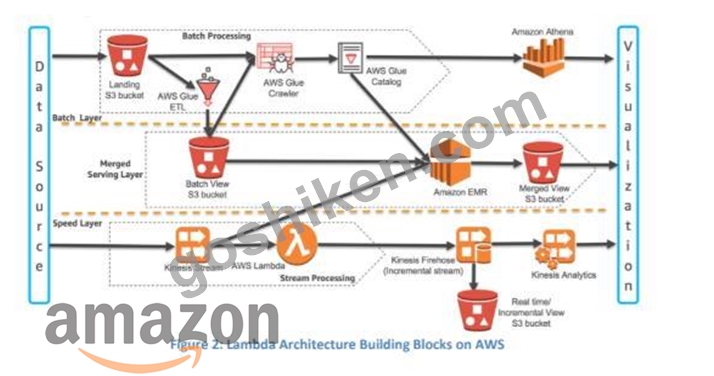
https://d1.awsstatic.com/whitepapers/lambda-architecure-on-for-batch-aws.pdf
質問 # 135
会社のデータ分析チームは、データベースに対してリアルタイムで複雑なクエリを実行する必要があります。チームが成長するにつれて、複雑なクエリにより本番トランザクションが遅くなります。現在の環境には、最大のインスタンスタイプを持つAmazon RDSデータベースがあり、パフォーマンスの問題が引き続き発生しています。
どのソリューションがコストを削減し、パフォーマンスの問題を解決しますか?
- A. 実稼働データベースのAmazon RDSリードレプリカを実装して、データ分析チームが使用し、RDSデータベースインスタンスのサイズを減らします。
- B. Amazon EC2インスタンスを実装して、運用データベースのクラスターを実行し、RDSデータベースインスタンスを削除します。
- C. より大きなAmazon RDSデータベースインスタンスタイプを実装し、制限値増加リクエストを送信してリザーブドインスタンスを適用する
- D. Amazon ElastiCacheを実装し、ElastiCacheに対して直接クエリを実行します
正解:D
質問 # 136
......
試験準備には欠かさない!トップクラスのAmazon AWS-Solutions-Associate日本語試験アプリ学習ガイド練習問題最新版:https://www.goshiken.com/Amazon/AWS-Solutions-Architect-Associate-JP-mondaishu.html