![]()
100%合格率保証付きで最高のDP-203日本語試験でリアル問題PDFがある[2023年10月]
DP-203日本語問題集で2023年最新のMicrosoft DP-203日本語試験問題
質問 # 49
専用の SQL プールで Twitter フィード データを分析できることを確認する必要があります。ソリューションは、顧客感情分析の要件を満たす必要があります。
順番に実行する必要がある 3 つのトランザクション SQL DDL コマンドはどれですか?回答するには、適切なコマンドをコマンドのリストから回答エリアに移動し、正しい順序で並べてください。
注: 複数の回答の選択肢が正しいです。選択した正しい注文のいずれかに対してクレジットを受け取ります。
正解:
解説:
Explanation
Scenario: Allow Contoso users to use PolyBase in an Azure Synapse Analytics dedicated SQL pool to query the content of the data records that host the Twitter feeds. Data must be protected by using row-level security (RLS). The users must be authenticated by using their own Azure AD credentials.
Box 1: CREATE EXTERNAL DATA SOURCE
External data sources are used to connect to storage accounts.
Box 2: CREATE EXTERNAL FILE FORMAT
CREATE EXTERNAL FILE FORMAT creates an external file format object that defines external data stored in Azure Blob Storage or Azure Data Lake Storage. Creating an external file format is a prerequisite for creating an external table.
Box 3: CREATE EXTERNAL TABLE AS SELECT
When used in conjunction with the CREATE TABLE AS SELECT statement, selecting from an external table imports data into a table within the SQL pool. In addition to the COPY statement, external tables are useful for loading data.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables
質問 # 50
次の展示に示すように、Azure DataFactoryインスタンスのバージョン管理を構成します。
ドロップダウンメニューを使用して、図に示されている情報に基づいて各ステートメントを完了する回答の選択肢を選択します。
注:正しい選択はそれぞれ1ポイントの価値があります。
正解:
解説:
Explanation
Letter Description automatically generated
Box 1: adf_publish
The Publish branch is the branch in your repository where publishing related ARM templates are stored and updated. By default, it's adf_publish.
Box 2: / dwh_batchetl/adf_publish/contososales
Note: RepositoryName (here dwh_batchetl): Your Azure Repos code repository name. Azure Repos projects contain Git repositories to manage your source code as your project grows. You can create a new repository or use an existing repository that's already in your project.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/source-control
質問 # 51
Azure Active Directory (Azure AD) 統合を使用して Azure Data Lake Storage Gen2 に自動的に接続する Azure Databricks クラスターを実装する必要があります。
新しいクラスターをどのように構成する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注: 正しい選択ごとに 1 ポイントの価値があります。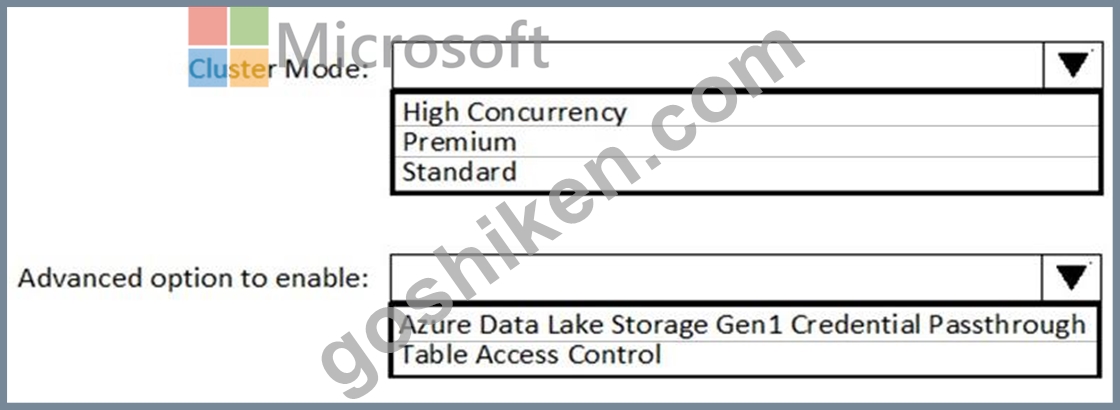
正解:
解説:
Reference:
https://docs.azuredatabricks.net/spark/latest/data-sources/azure/adls-passthrough.html
質問 # 52
会社の人材(MR)部門向けのデータマートを設計しています。データマートには、情報と従業員の取引が含まれます。ソースシステムから、次のフィールドを持つフラット抽出があります。
* 従業員ID
* ファーストネーム
* 苗字
*受信者
* GrossArnount
* TransactionID
* GovernmentID
* NetAmountPaid
* TransactionDate
データマート専用のAzureSynapseアナリティクス専用SQLプールで開始スキーマデータモデルを設計する必要があります。
どの2つのテーブルを作成する必要がありますか?それぞれの正解は、ソリューションの一部を示しています。
- A. 従業員のディメンションテーブル
- B. トランザクションのディメンションテーブル
- C. EmployeeTransactionまでのディメンションテーブル
- D. トランザクションのファクトテーブル
- E. 従業員用の生地
正解:A、D
解説:
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-overview
質問 # 53
WS1 という名前の Azure Synapse Analytics ワークスペースがあります。
次の形式の JSON 形式のファイルを含む Azure Data Lake Storage Gen2 コンテナーがあります。
ファイルを読み取るには、WS1 のサーバーレス SQL プールを使用する必要があります。
Transact-SQL ステートメントをどのように完成させる必要がありますか? 答えるには、適切な値を正しいターゲットにドラッグします。各値は、1 回以上使用することも、まったく使用しないこともできます。ペイン間の分割バーをドラッグするか、コンテンツを表示するためにスクロールする必要がある場合があります。
注: それぞれの正しい選択は 1 ポイントの価値があります。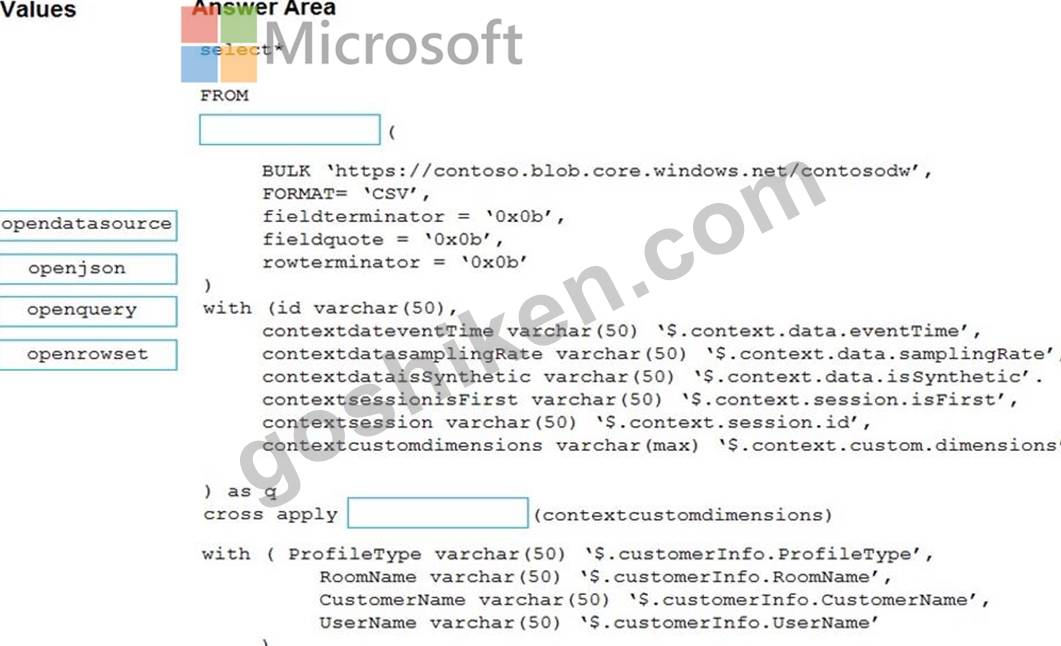
正解:
解説:
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-single-csv-file
https://docs.microsoft.com/en-us/sql/relational-databases/json/import-json-documents-into-sql-server
質問 # 54
Azure データ ファクトリがあります。
パイプライン実行データが 120 日間保持されることを確認する必要があります。ソリューションでは、Kusto クエリ言語を使用してデータをクエリできることを確認する必要があります。
順番に実行する必要がある 4 つのアクションはどれですか?回答するには、アクションのリストから適切なアクションを回答エリアに移動し、正しい順序で並べてください。
注: 複数の回答の選択肢が正しいです。選択した正しい注文のいずれかに対してクレジットを受け取ります。
正解:
解説:
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
質問 # 55
Pool1という名前のAzureSynapse Analytics専用SQLプールと、DB1という名前のデータベースがあります。 DB1には、Table1という名前のファクトテーブルが含まれています。
表1でデータスキューの範囲を特定する必要があります。
Synapse Studioで何をすべきですか?
- A. 組み込みプールに接続し、sysdm_pdw_sys_infoを照会します。
- B. プールに接続してください! sys.dm_pdw_nodes_db_partition_statsをクエリします。
- C. Pool1に接続し、DBCCCHECKALLOCを実行します。
- D. 組み込みプールに接続し、DBCCCHECKALLOCを実行します。
正解:B
解説:
Microsoft recommends use of sys.dm_pdw_nodes_db_partition_stats to analyze any skewness in the data.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet
質問 # 56
Azure Databrick クラスターのアプリケーション メトリック、ストリーミング クエリ イベント、およびアプリケーション ログ メッセージを収集する必要があります。
どのタイプのライブラリとワークスペースを実装する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注: 正しい選択ごとに 1 ポイントの価値があります。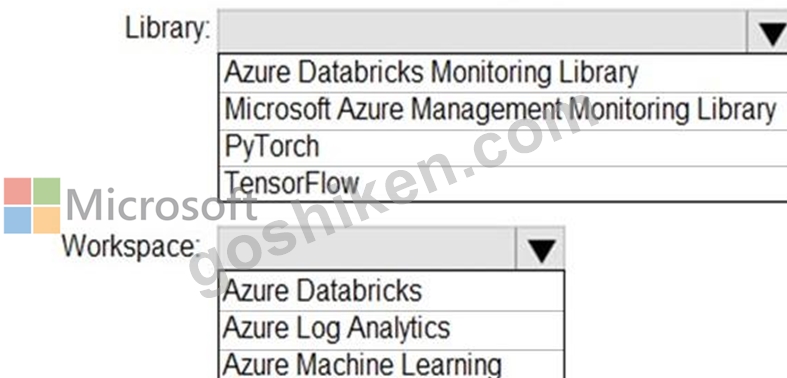
正解:
解説: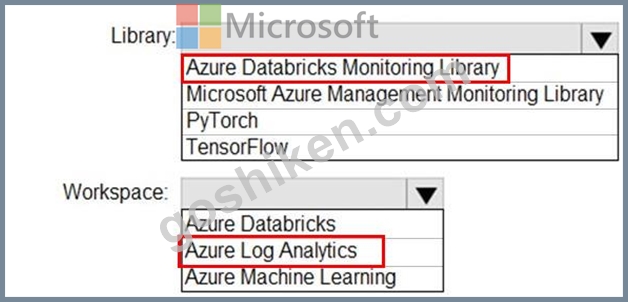
Reference:
https://docs.microsoft.com/en-us/azure/architecture/databricks-monitoring/application-logs
質問 # 57
Azure Active Directory (Azure AD) 統合を使用して Azure Data Lake Storage Gen2 に自動的に接続する Azure Databricks クラスターを実装する必要があります。
新しいクラスターをどのように構成する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注: 正しい選択ごとに 1 ポイントの価値があります。
正解:
解説: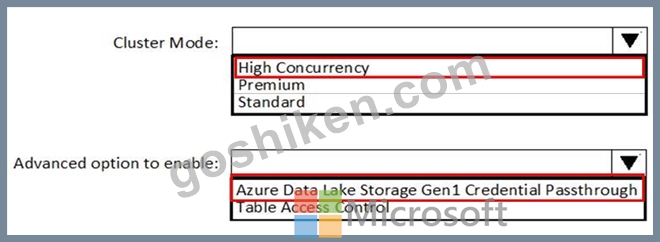
Reference:
https://docs.azuredatabricks.net/spark/latest/data-sources/azure/adls-passthrough.html
質問 # 58
小売店テーブルの代理キーを実装する必要があります。ソリューションは、販売トランザクション データセットの要件を満たす必要があります。
何を作成する必要がありますか?
- A. FOREIGN KEY 制約のあるテーブル
- B. ユーザー定義の SEQUENCE オブジェクト
- C. システム バージョン管理されたテンポラル テーブル
- D. IDENTITY プロパティを持つテーブル
正解:D
解説:
Scenario: Implement a surrogate key to account for changes to the retail store addresses.
A surrogate key on a table is a column with a unique identifier for each row. The key is not generated from the table data.
Data modelers like to create surrogate keys on their tables when they design data warehouse models.
You can use the IDENTITY property to achieve this goal simply and effectively without affecting load performance.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-identity
Topic 1, Contoso
Transactional Date
Contoso has three years of customer, transactional, operation, sourcing, and supplier data comprised of 10 billion records stored across multiple on-premises Microsoft SQL Server servers. The SQL server instances contain data from various operational systems. The data is loaded into the instances by using SQL server integration Services (SSIS) packages.
You estimate that combining all product sales transactions into a company-wide sales transactions dataset will result in a single table that contains 5 billion rows, with one row per transaction.
Most queries targeting the sales transactions data will be used to identify which products were sold in retail stores and which products were sold online during different time period. Sales transaction data that is older than three years will be removed monthly.
You plan to create a retail store table that will contain the address of each retail store. The table will be approximately 2 MB. Queries for retail store sales will include the retail store addresses.
You plan to create a promotional table that will contain a promotion ID. The promotion ID will be associated to a specific product. The product will be identified by a product ID. The table will be approximately 5 GB.
Streaming Twitter Data
The ecommerce department at Contoso develops and Azure logic app that captures trending Twitter feeds referencing the company's products and pushes the products to Azure Event Hubs.
Planned Changes
Contoso plans to implement the following changes:
* Load the sales transaction dataset to Azure Synapse Analytics.
* Integrate on-premises data stores with Azure Synapse Analytics by using SSIS packages.
* Use Azure Synapse Analytics to analyze Twitter feeds to assess customer sentiments about products.
Sales Transaction Dataset Requirements
Contoso identifies the following requirements for the sales transaction dataset:
* Partition data that contains sales transaction records. Partitions must be designed to provide efficient loads by month. Boundary values must belong: to the partition on the right.
* Ensure that queries joining and filtering sales transaction records based on product ID complete as quickly as possible.
* Implement a surrogate key to account for changes to the retail store addresses.
* Ensure that data storage costs and performance are predictable.
* Minimize how long it takes to remove old records.
Customer Sentiment Analytics Requirement
Contoso identifies the following requirements for customer sentiment analytics:
* Allow Contoso users to use PolyBase in an A/ure Synapse Analytics dedicated SQL pool to query the content of the data records that host the Twitter feeds. Data must be protected by using row-level security (RLS). The users must be authenticated by using their own A/ureAD credentials.
* Maximize the throughput of ingesting Twitter feeds from Event Hubs to Azure Storage without purchasing additional throughput or capacity units.
* Store Twitter feeds in Azure Storage by using Event Hubs Capture. The feeds will be converted into Parquet files.
* Ensure that the data store supports Azure AD-based access control down to the object level.
* Minimize administrative effort to maintain the Twitter feed data records.
* Purge Twitter feed data records;itftaitJ are older than two years.
Data Integration Requirements
Contoso identifies the following requirements for data integration:
Use an Azure service that leverages the existing SSIS packages to ingest on-premises data into datasets stored in a dedicated SQL pool of Azure Synaps Analytics and transform the data.
Identify a process to ensure that changes to the ingestion and transformation activities can be version controlled and developed independently by multiple data engineers.
質問 # 59
storage1 という名前の Azure Data Lake Storage Gen 2 アカウントがあります。
storage1 のコンテンツにアクセスするためのソリューションを推奨する必要があります。ソリューションは、次の要件を満たす必要があります。
リストと読み取りのアクセス許可は、ストレージ アカウント レベルで付与する必要があります。
storage1 内の個々のオブジェクトに追加のアクセス許可を適用できます。
認証には、Microsoft Entra の一部である Microsoft Azure Active Directory (Azure AD) のセキュリティ プリンシパルを使用する必要があります。
何を使うべきですか?答えるには、適切なコンポーネントを正しい要件にドラッグします。各コンポーネントは、1 回以上使用することも、まったく使用しないこともできます。ペイン間の分割バーをドラッグするか、コンテンツを表示するためにスクロールする必要がある場合があります。
注: それぞれの正しい選択は 1 ポイントの価値があります。
正解:
解説:
質問 # 60
ストレージアカウントコンテナビューは、Refdata展示に表示されます。 ([Refdata]タブをクリックします。)新しい参照データを取得するようにStreamAnalyticsジョブを構成する必要があります。何を構成する必要がありますか?回答するには、回答領域で適切なオプションを選択してください。注:正しい選択はそれぞれ1ポイントの価値があります。
正解:
解説:
Answer as below
質問 # 61
製品販売トランザクションのパーティションを設計する必要があります。ソリューションは、販売トランザクション データセットの要件を満たす必要があります。
ソリューションには何を含める必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注: 正しい選択ごとに 1 ポイントの価値があります。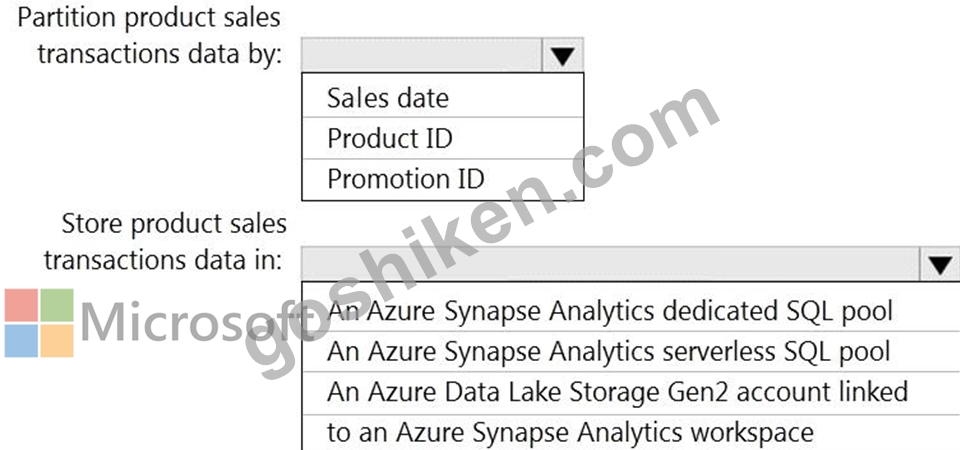
正解:
解説: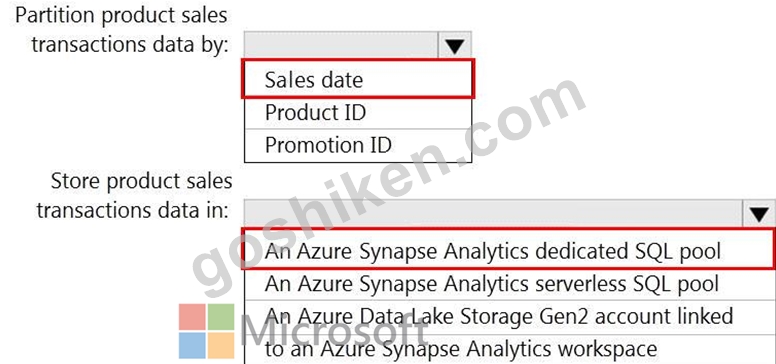
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-overview-what-is
質問 # 62
データフローを含むAzureDataFactoryパイプラインがあります。データフローには次の式が含まれています。
正解:
解説:
質問 # 63
ユーザー定義のローカルプロセスを実行するAzureDatabricksクラスターを設計しています。次の要件を満たすクラスター構成を推奨する必要があります。
*クエリの待ち時間を最小限に抑えます。
*クラスター上で同時にキューを実行できるユーザーの数を最大化して、他の要件を損なうことなく全体的なコストを削減するどのクラスタータイプを推奨する必要がありますか?
- A. 自動終了の標準
- B. 自動スケーリングによる高い同時実行性
- C. 自動終了による高い同時実行性
- D. 自動スケーリングを使用した標準
正解:B
解説:
A High Concurrency cluster is a managed cloud resource. The key benefits of High Concurrency clusters are that they provide fine-grained sharing for maximum resource utilization and minimum query latencies.
Databricks chooses the appropriate number of workers required to run your job. This is referred to as autoscaling. Autoscaling makes it easier to achieve high cluster utilization, because you don't need to provision the cluster to match a workload.
Reference:
https://docs.microsoft.com/en-us/azure/databricks/clusters/configure
質問 # 64
Azure Synapse Analytics サーバーレス SQL プール、Azure Synapse Analytics 専用 SQL プール、Apache Spark プール、および Azure Data Lake Storage Gen2 アカウントがあります。
レイク データベースにテーブルを作成する必要があります。テーブルは、サーバーレス SQL プールと Spark プールの両方で使用できる必要があります。
テーブルを作成する場所と、テーブル内のデータにはどのファイル形式を使用する必要がありますか? 回答するには、回答で適切なオプションを選択します。
注: それぞれの正しい選択は 1 ポイントの価値があります。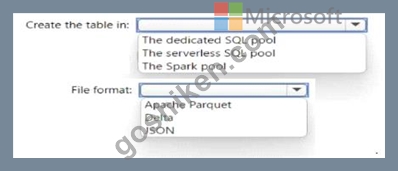
正解:
解説: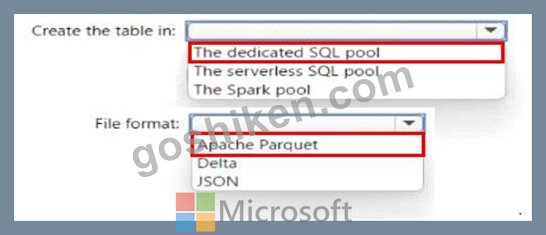
質問 # 65
1時間ごとにトリガーされるAzureDataFactoryパイプラインがあります。
パイプラインは過去7日間で100%成功しています。
パイプラインの実行は失敗し、15分間隔で発生する2回の再試行も失敗します。 3番目の失敗は、次のエラーを返します。
エラーの考えられる原因は何ですか?
- A. year = 2021 / month = 01 / day = 10 / hour = 06の生成に使用されたパラメーターが正しくありませんでした。
- B. 2021年1月10日の06:00から07:00まで、wwi / BIKES / CARBONにデータがありませんでした。
- C. 2021年1月10日06:00から07:00まで、wwi / BIKES / CARBONのデータのファイル形式が正しくありませんでした。
- D. パイプラインのトリガーが早すぎました。
正解:A
質問 # 66
Azure Databrick クラスターのアプリケーション メトリック、ストリーミング クエリ イベント、およびアプリケーション ログ メッセージを収集する必要があります。
どのタイプのライブラリとワークスペースを実装する必要がありますか?回答するには、回答エリアで適切なオプションを選択してください。
注: 正しい選択ごとに 1 ポイントの価値があります。
正解:
解説: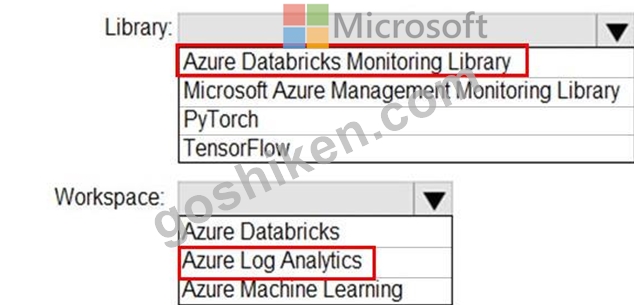
References:
https://docs.microsoft.com/en-us/azure/architecture/databricks-monitoring/application-logs
質問 # 67
Azure Data Factory にセルフホステッド統合ランタイムがあります。
統合ランタイムの現在のステータスは次の構成になっています。
ステータス: 実行中
タイプ: セルフホスト型
バージョン: 4.4.7292.1
実行中/登録済みノード: 1/1
高可用性の有効化: False
リンク数: 0
キューの長さ: 0
平均キュー時間。0.00秒
統合ランタイムには次のノードの詳細があります。
名前:XM
ステータス: 実行中
バージョン: 4.4.7292.1
利用可能なメモリ: 7697MB
CPU使用率: 6%
ネットワーク (受信/送信): 1.21KBps/0.83KBps
同時ジョブ数 (実行中/制限): 2/14
役割: 派遣者/ワーカー
認証情報のステータス: 同期中
ドロップダウン メニューを使用して、表示された情報に基づいて各ステートメントを完成させる回答の選択肢を選択します。
注: 正しく選択するたびに 1 ポイントの価値があります。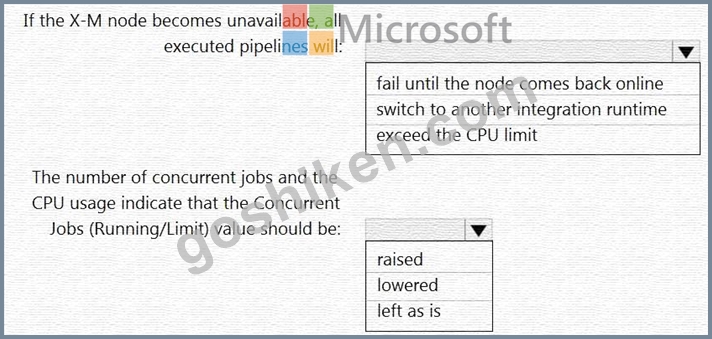
正解:
解説: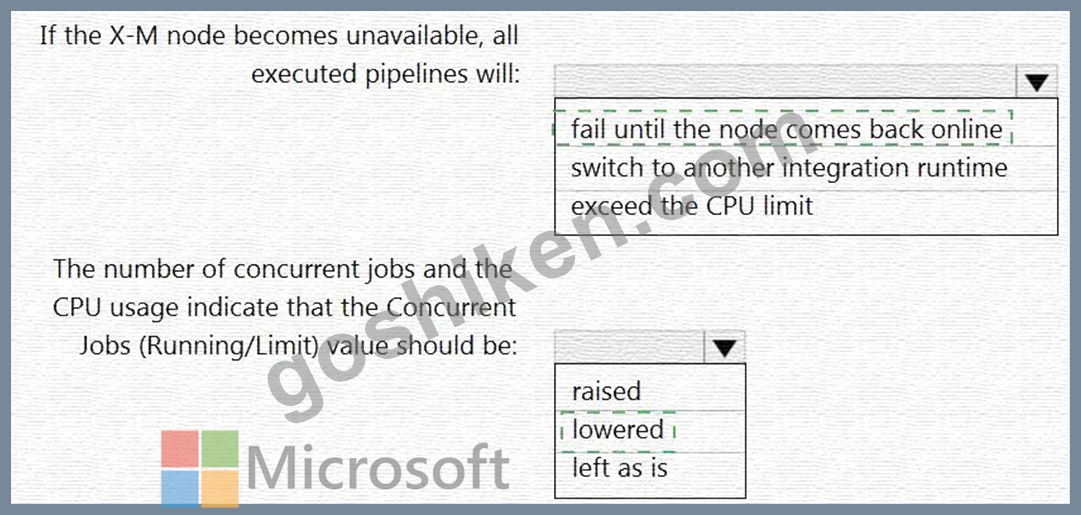
Explanation
Box 1: fail until the node comes back online
We see: High Availability Enabled: False
Note: Higher availability of the self-hosted integration runtime so that it's no longer the single point of failure in your big data solution or cloud data integration with Data Factory.
Box 2: lowered
We see:
Concurrent Jobs (Running/Limit): 2/14
CPU Utilization: 6%
Note: When the processor and available RAM aren't well utilized, but the execution of concurrent jobs reaches a node's limits, scale up by increasing the number of concurrent jobs that a node can run Reference:
https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
質問 # 68
......
無料DP-203日本語別格な問題集をダウンロード:https://www.goshiken.com/Microsoft/DP-203J-mondaishu.html