![]()
[2024年05月24日] DP-100 PDF問題集にはあなたに不可欠なDP-100試験解答を合格に繋ぐ!
DP-100PDF解答で完璧な予見DP-100練習試験問題
DP-100 試験には、データ探索、データ準備、データモデリング、機械学習、データ可視化など、データサイエンスに関連する様々なトピックが含まれます。また、試験はデータソリューションに使用される Azure サービスに関する候補者の知識をテストします。これには、Azure Machine Learning、Azure Data Factory、Azure Stream Analytics、Azure Databricks などが含まれます。試験形式には、多肢選択問題、ケーススタディ、実践的な演習が含まれます。
Microsoft DP-100認定試験は、データサイエンスの分野で高度に認識されている認定です。 Azure Technologiesを使用してデータサイエンスソリューションを設計および実装するために必要なスキルと知識を候補者に提供するように設計されています。この認定を達成することにより、候補者はこの分野での専門知識を実証し、業界で新しい機会を開くことでキャリアの見通しを高めることができます。
DP-100試験では、データの摂取と処理ソリューションの設計と実装、機械学習モデルの設計と実装、データストレージソリューションの設計と実装、データ視覚化ソリューションの設計と実装など、データサイエンスに関連するさまざまなトピックをカバーしています。この試験では、Azure Machine Learning、Azure Databricks、Azure Stream Analytics、Azure Data FactoryなどのAzureサービスに関する候補者の知識も評価します。
質問 # 216
You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to 10.
You need to select the bias and variance properties of the model with varying tree depth values.
Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area.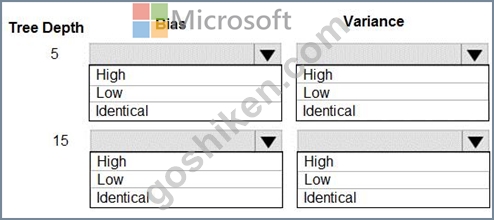
正解:
解説: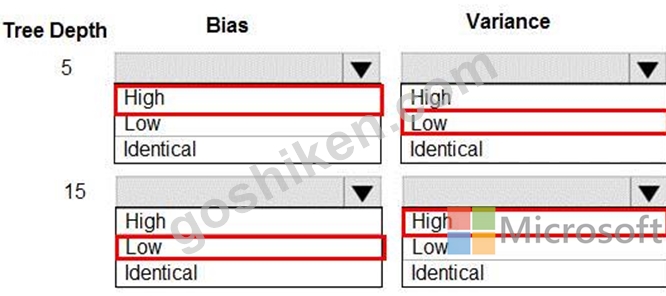
Explanation:
In decision trees, the depth of the tree determines the variance. A complicated decision tree (e.g. deep) has low bias and high variance.
Note: In statistics and machine learning, the bias-variance tradeoff is the property of a set of predictive models whereby models with a lower bias in parameter estimation have a higher variance of the parameter estimates across samples, and vice versa. Increasing the bias will decrease the variance. Increasing the variance will decrease the bias.
References:
https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning/
質問 # 217
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.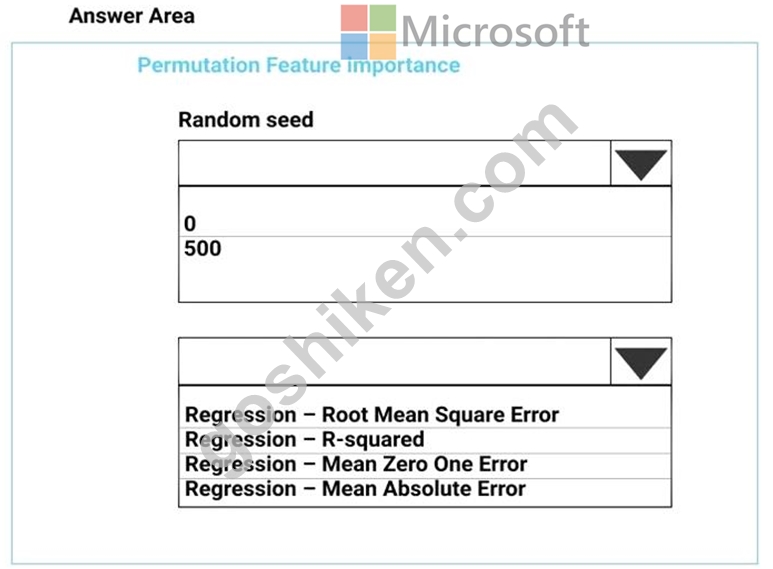
正解:
解説: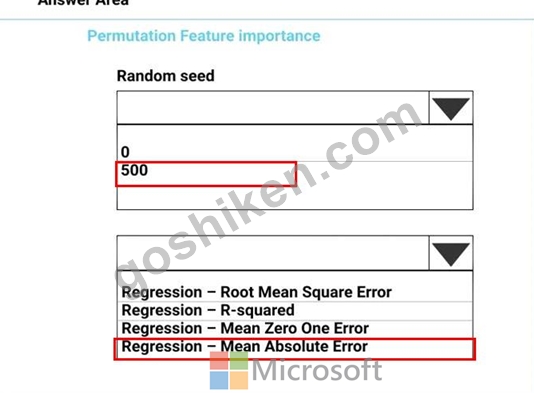
Explanation:
Box 1: 500
For Random seed, type a value to use as seed for randomization. If you specify 0 (the default), a number is generated based on the system clock.
A seed value is optional, but you should provide a value if you want reproducibility across runs of the same experiment.
Here we must replicate the findings.
Box 2: Mean Absolute Error
Scenario: Given a trained model and a test dataset, you must compute the Permutation Feature Importance scores of feature variables. You need to set up the Permutation Feature Importance module to select the correct metric to investigate the model's accuracy and replicate the findings.
Regression. Choose one of the following: Precision, Recall, Mean Absolute Error , Root Mean Squared Error, Relative Absolute Error, Relative Squared Error, Coefficient of Determination References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/permutation-feature-importance
質問 # 218
You need to implement a new cost factor scenario for the ad response models as illustrated in the performance curve exhibit.
Which technique should you use?
- A. Set the threshold to 0.75 and retrain if weighted Kappa deviates +/- 5% from 0.15.
- B. Set the threshold to 0.05 and retrain if weighted Kappa deviates +/- 5% from 0.5.
- C. Set the threshold to 0.2 and retrain if weighted Kappa deviates +/- 5% from 0.6.
- D. Set the threshold to 0.5 and retrain if weighted Kappa deviates +/- 5% from 0.45.
正解:D
解説:
Scenario:
Performance curves of current and proposed cost factor scenarios are shown in the following diagram:
The ad propensity model uses a cut threshold is 0.45 and retrains occur if weighted Kappa deviated from 0.1 +/- 5%.
質問 # 219
You have a Python data frame named salesData in the following format:
The data frame must be unpivoted to a long data format as follows:
You need to use the pandas.melt() function in Python to perform the transformation.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.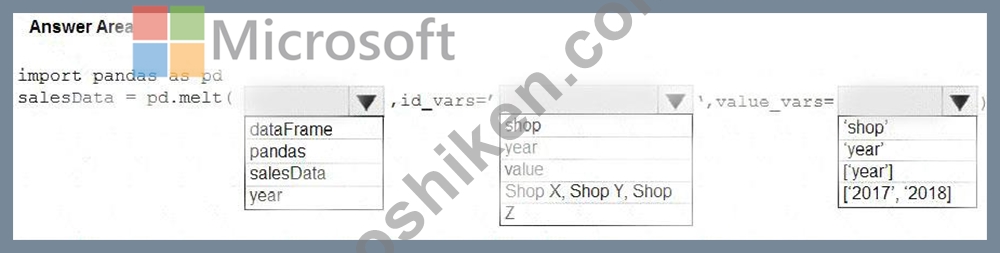
正解:
解説:
Explanation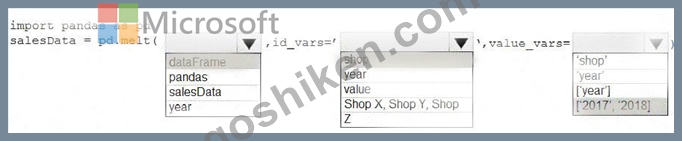
Box 1: dataFrame
Syntax: pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)[source] Where frame is a DataFrame Box 2: shop Paramter id_vars id_vars : tuple, list, or ndarray, optional Column(s) to use as identifier variables.
Box 3: ['2017','2018']
value_vars : tuple, list, or ndarray, optional
Column(s) to unpivot. If not specified, uses all columns that are not set as id_vars.
Example:
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}})
pd.melt(df, id_vars=['A'], value_vars=['B', 'C'])
A variable value
0 a B 1
1 b B 3
2 c B 5
3 a C 2
4 b C 4
5 c C 6
References:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.melt.html
質問 # 220
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.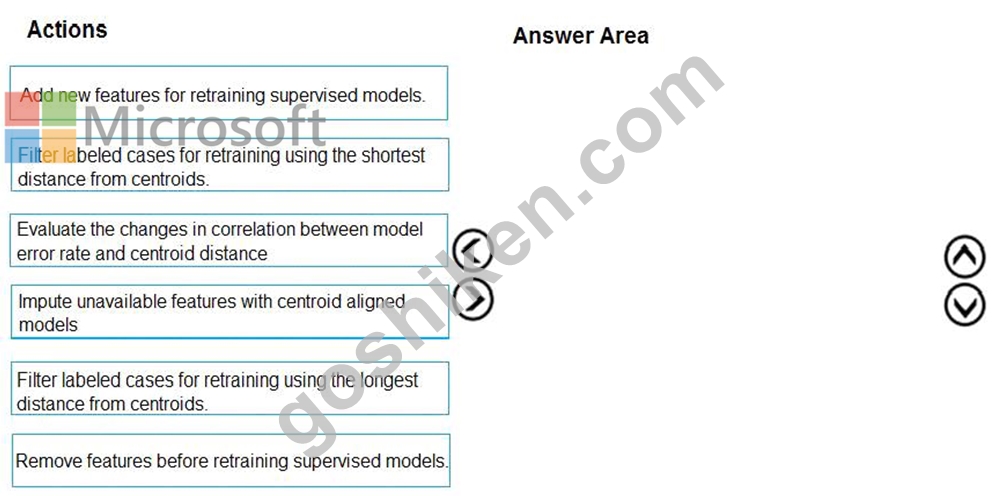
正解:
解説: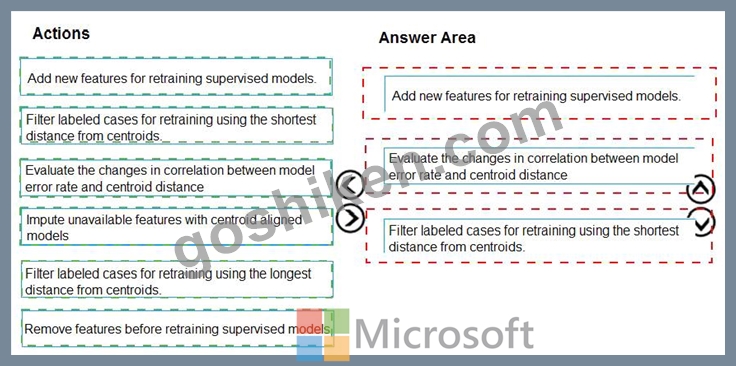
Explanation
Scenario:
Experiments for local crowd sentiment models must combine local penalty detection data.
Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual crowd sentiment models will detect similar sounds.
Note: Evaluate the changed in correlation between model error rate and centroid distance In machine learning, a nearest centroid classifier or nearest prototype classifier is a classification model that assigns to observations the label of the class of training samples whose mean (centroid) is closest to the observation.
References:
https://en.wikipedia.org/wiki/Nearest_centroid_classifier
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/sweep-clustering
質問 # 221
You create a pipeline in designer to train a model that predicts automobile prices.
Because of non-linear relationships in the data, the pipeline calculates the natural log (Ln) of the prices in the training data, trains a model to predict this natural log of price value, and then calculates the exponential of the scored label to get the predicted price.
The training pipeline is shown in the exhibit. (Click the Training pipeline tab.) Training pipeline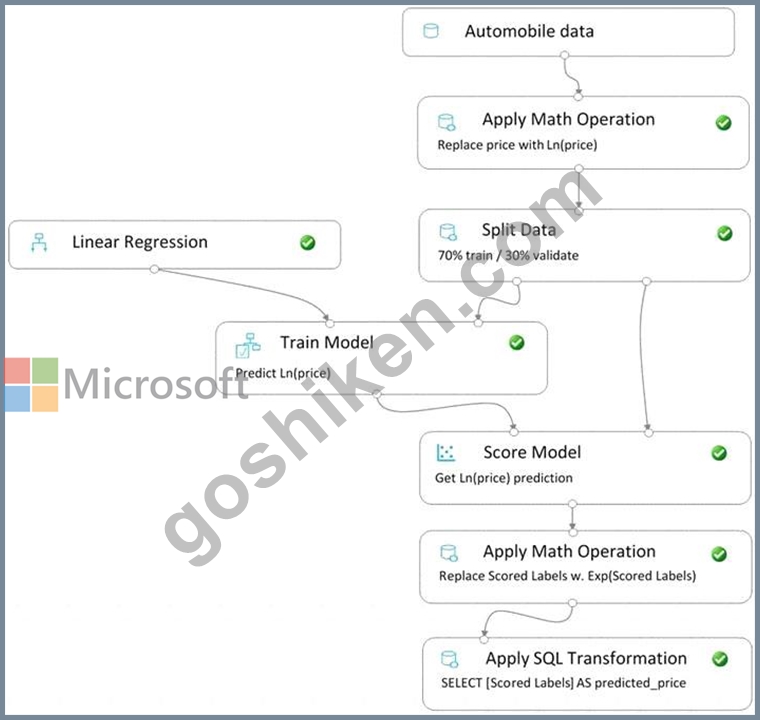
You create a real-time inference pipeline from the training pipeline, as shown in the exhibit. (Click the Real-time pipeline tab.) Real-time pipeline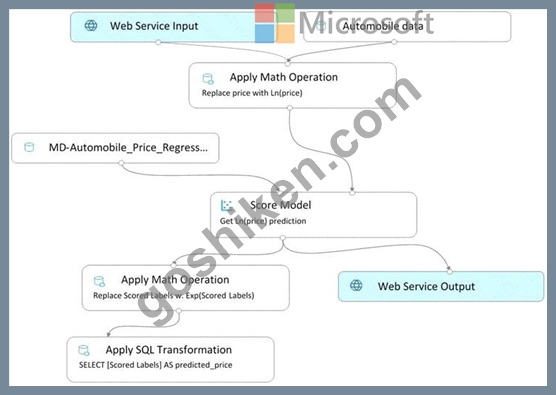
You need to modify the inference pipeline to ensure that the web service returns the exponential of the scored label as the predicted automobile price and that client applications are not required to include a price value in the input values.
Which three modifications must you make to the inference pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Remove the Apply SQL Transformation module from the data flow.
- B. Add a Select Columns module before the Score Model module to select all columns other than price.
- C. Connect the output of the Apply SQL Transformation to the Web Service Output module.
- D. Remove the Apply Math Operation module that replaces price with its natural log from the data flow.
- E. Replace the Web Service Input module with a data input that does not include the price column.
- F. Replace the training dataset module with a data input that does not include the price column.
正解:B、C、D
質問 # 222
You are a lead data scientist for a project that tracks the health and migration of birds. You create a multi-image classification deep learning model that uses a set of labeled bird photos collected by experts. You plan to use the model to develop a cross-platform mobile app that predicts the species of bird captured by app users.
You must test and deploy the trained model as a web service. The deployed model must meet the following requirements:
An authenticated connection must not be required for testing.
The deployed model must perform with low latency during inferencing.
The REST endpoints must be scalable and should have a capacity to handle large number of requests when multiple end users are using the mobile application.
You need to verify that the web service returns predictions in the expected JSON format when a valid REST request is submitted.
Which compute resources should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
正解:
解説: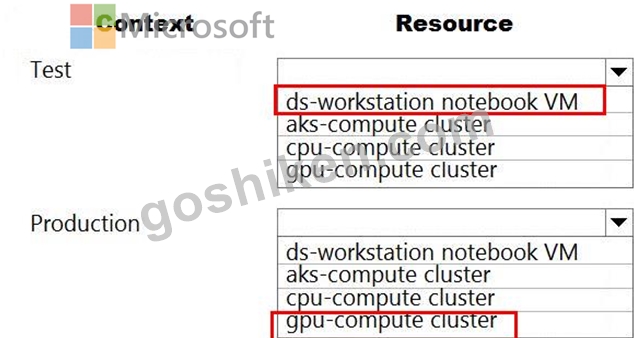
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/data-science-virtual-machine/dsvm-common-identity
https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/ai/training-deep-learning
質問 # 223
You create a new Azure Databricks workspace.
You configure a new cluster for long-running tasks with mixed loads on the compute cluster as shown in the image below.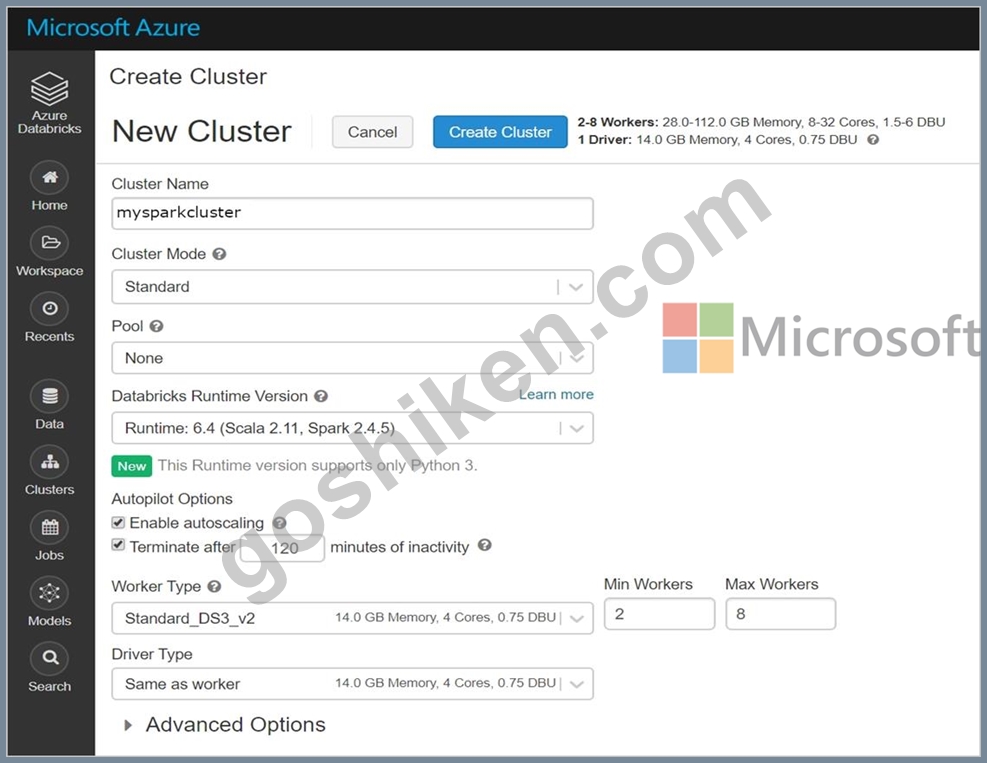
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
正解:
解説:
Reference:
https://docs.databricks.com/clusters/configure.html
質問 # 224
You have an existing GitHub repository containing Azure Machine Learning project files.
You need to clone the repository to your Azure Machine Learning shared workspace file system.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.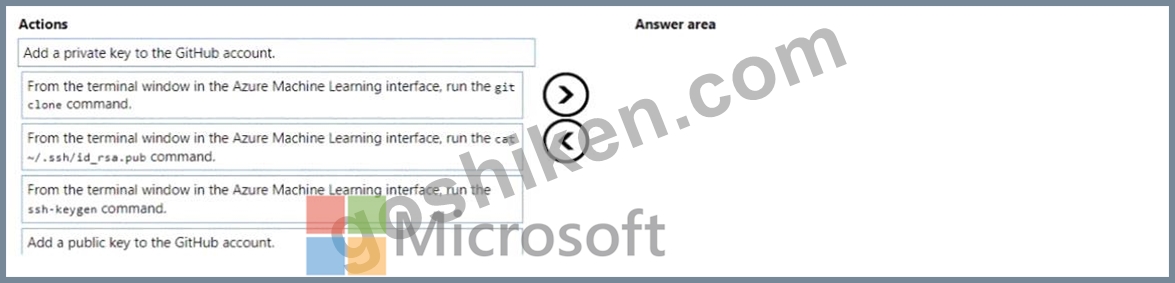
正解:
解説:
Explanation
質問 # 225
You use an Azure Machine Learning workspace.
You create the following Python code:
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
正解:
解説:
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.scriptrunconfig
https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.environment.environment
質問 # 226
You create a training pipeline using the Azure Machine Learning designer. You upload a CSV file that contains the data from which you want to train your model. You need to use the designer to create a pipeline that includes steps to perform the following tasks:
* Select the training features using the pandas filter method.
* Train a model based on the naive.bayes.GaussianNB algorithm.
* Return only the Scored Labels column by using the query select [scored Labels] froh t1; Which modules should you use? To answer, drag the appropriate modules to the appropriate locations. Each module name may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
正解:
解説:
質問 # 227
You are creating a machine learning model in Python. The provided dataset contains several numerical columns and one text column. The text column represents a product's category. The product category will always be one of the following:
* Bikes
* Cars
* Vans
* Boats
You are building a regression model using the scikit-learn Python package.
You need to transform the text data to be compatible with the scikit-learn Python package.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.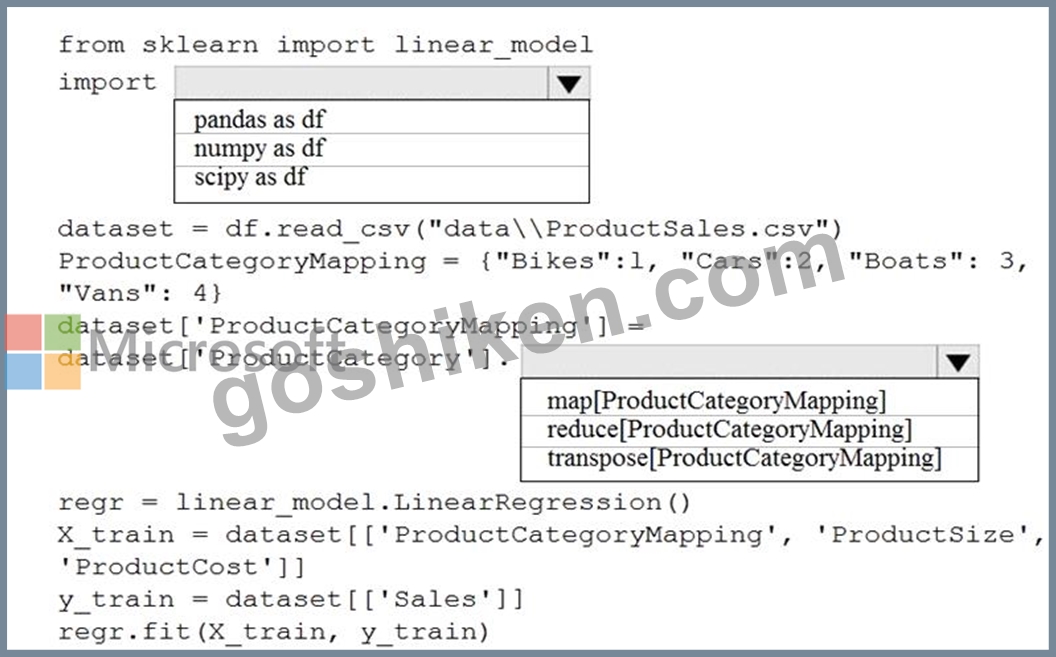
正解:
解説: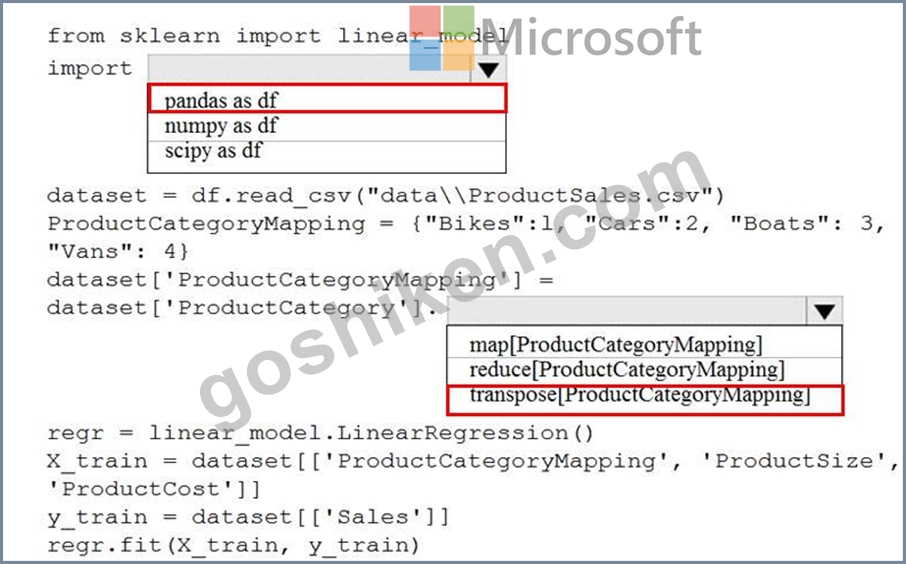
Explanation:
Box 1: pandas as df
Pandas takes data (like a CSV or TSV file, or a SQL database) and creates a Python object with rows and columns called data frame that looks very similar to table in a statistical software (think Excel or SPSS for example.
Box 2: transpose[ProductCategoryMapping]
Reshape the data from the pandas Series to columns.
Reference:
https://datascienceplus.com/linear-regression-in-python/
質問 # 228
You create a binary classification model to predict whether a person has a disease.
You need to detect possible classification errors.
Which error type should you choose for each description? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
正解:
解説:

Reference:
https://developers.google.com/machine-learning/crash-course/classification/true-false-positive-negative
質問 # 229
You need to replace the missing data in the AccessibilityToHighway columns.
How should you configure the Clean Missing Data module? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.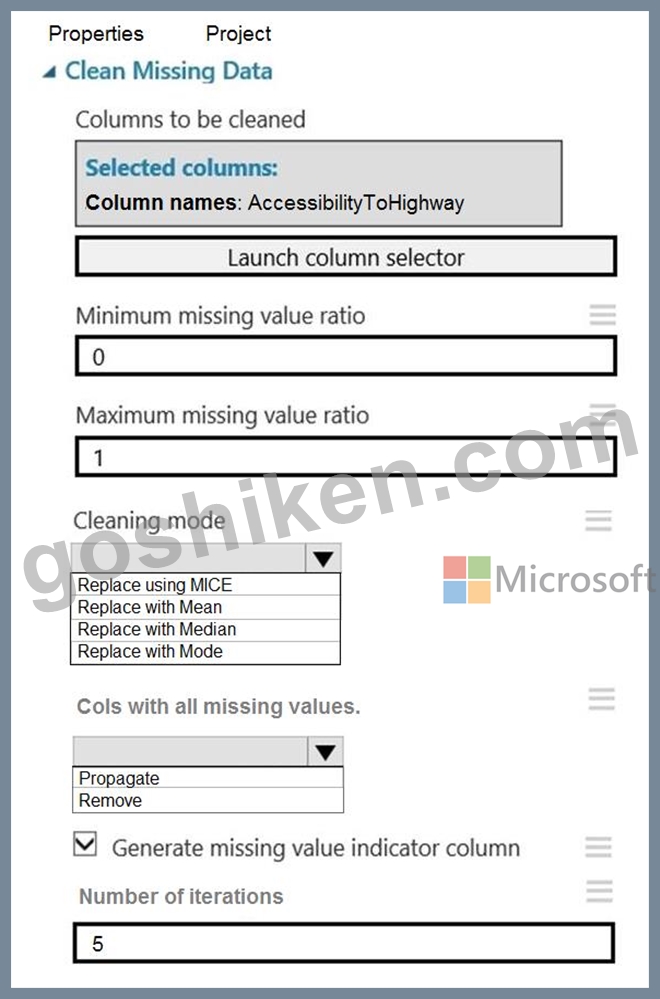
正解:
解説: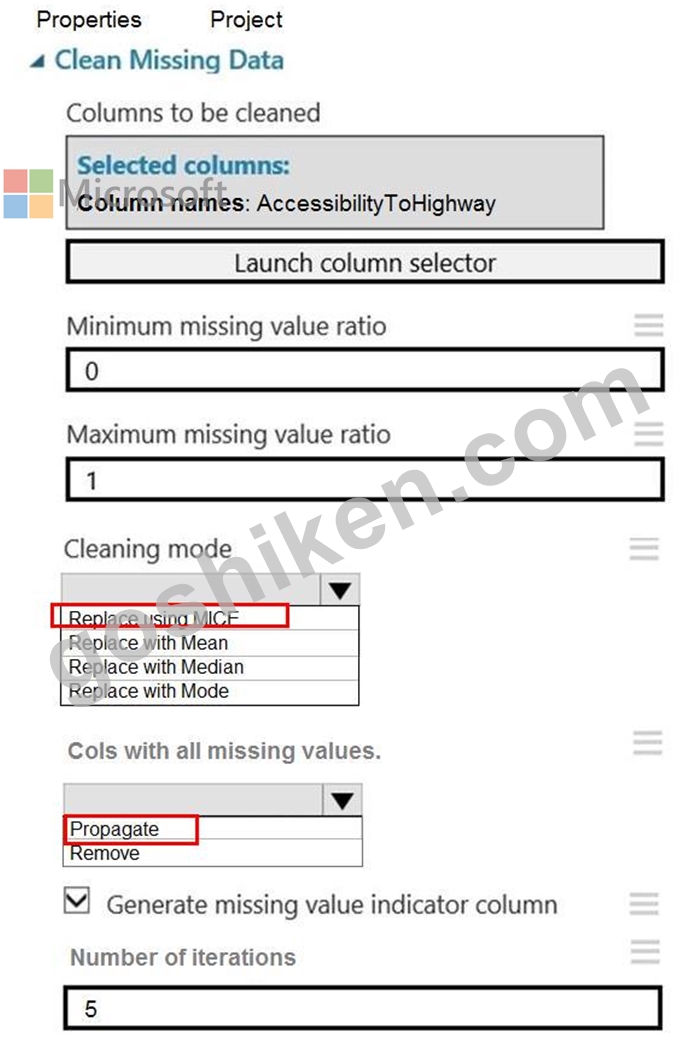
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
質問 # 230
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it as a result, these questions will not appear in the review screen.
You train and register an Azure Machine Learning model.
You plan to deploy the model to an online end point.
You need to ensure that applications will be able to use the authentication method with a non-expiring artifact to access the model.
Solution:
Create a Kubernetes online endpoint and set the value of its auth-mode parameter to amyl Token. Deploy the model to the online endpoint.
Does the solution meet the goal?
- A. No
- B. Yes
正解:A
質問 # 231
You are preparing to build a deep learning convolutional neural network model for image classification. You create a script to train the model using CUDA devices.
You must submit an experiment that runs this script in the Azure Machine Learning workspace.
The following compute resources are available:
a Microsoft Surface device on which Microsoft Office has been installed. Corporate IT policies prevent the installation of additional software a Compute Instance named ds-workstation in the workspace with 2 CPUs and 8 GB of memory an Azure Machine Learning compute target named cpu-cluster with eight CPU-based nodes an Azure Machine Learning compute target named gpu-cluster with four CPU and GPU-based nodes You need to specify the compute resources to be used for running the code to submit the experiment, and for running the script in order to minimize model training time.
Which resources should the data scientist use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.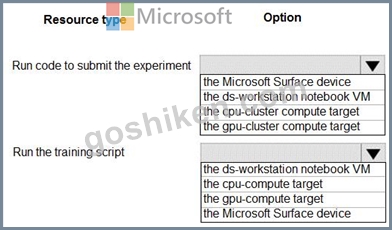
正解:
解説: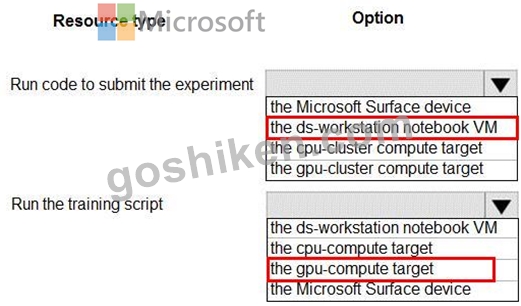
質問 # 232
You plan to use the Hyperdrive feature of Azure Machine Learning to determine the optimal hyperparameter values when training a model.
You must use Hyperdrive to try combinations of the following hyperparameter values:
* learning_rate: any value between 0.001 and 0.1
* batch_size: 16, 32, or 64
You need to configure the search space for the Hyperdrive experiment.
Which two parameter expressions should you use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. a uniform expression for batch_size
- B. a choice expression for learning_rate
- C. a choice expression for batch_size
- D. a uniform expression for learning_rate
- E. a normal expression for batch_size
正解:C、D
解説:
Explanation
B: Continuous hyperparameters are specified as a distribution over a continuous range of values. Supported distributions include:
* uniform(low, high) - Returns a value uniformly distributed between low and high D: Discrete hyperparameters are specified as a choice among discrete values. choice can be:
* one or more comma-separated values
* a range object
* any arbitrary list object
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-tune-hyperparameters
質問 # 233
You create an Azure Machine Learning compute resource to train models. The compute resource is configured as follows:
* Minimum nodes: 2
* Maximum nodes: 4
You must decrease the minimum number of nodes and increase the maximum number of nodes to the following values:
* Minimum nodes: 0
* Maximum nodes: 8
You need to reconfigure the compute resource.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Use the Azure Machine Learning studio.
- B. Run the refresh_state() method of the BatchCompute class in the Python SDK.
- C. Run the update method of the AmlCompute class in the Python SDK.
- D. Use the Azure Machine Learning designer.
- E. Use the Azure portal.
正解:A、C、E
解説:
A: You can manage assets and resources in the Azure Machine Learning studio.
B: The update(min_nodes=None, max_nodes=None, idle_seconds_before_scaledown=None) of the AmlCompute class updates the ScaleSettings for this AmlCompute target.
C: To change the nodes in the cluster, use the UI for your cluster in the Azure portal.
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.compute.amlcompute(class)
質問 # 234
......
DP-100リアル試験問題と正確なDesigning and Implementing a Data Science Solution on AzurePDF解答:https://www.goshiken.com/Microsoft/DP-100-mondaishu.html
リアルMicrosoft試験の素晴らしい練習問題集でDP-100試験:https://drive.google.com/open?id=10CG0NoOrB0Xc2vag5k5EYZAdtpIW-Nhj